
- 배치 처리 시에는 대량의 데이터를 처리하는 경우가 대부분이다.
- 하지만 많은 개발자가 배치 처리 성능에 대해 쉽게 생각한다.
- 100개의 데이터는 한번에 처리할 수 있지만 1000만개의 데이터는 한번에 처리 할 수 없다.
- 그래서 페이징 처리를 해서 청크 단위로 처리한다.
- 보통 mysql에서 청크 처리를 하려면 페이징 처리를 할 것 이다.
- offset, limit 방식을 생각하겠지만 이는 좋지 않은 방법이다.
- offset이 뒤로 갈수록 읽어야하는 데이터가 많고 앞에 읽은 데이터는 그냥 버려진다.
- zeroOffsetItemReader
- = cursor 페이징
- jdbcCursorItemReader. (권장)
- native Query를 써야한다.
- 안전한 방식 =>
Exposed를 사용했다.
- JPACurosrItemReader
- 권장하지 않는다. 서버 데이터를 모두 올린 뒤 서버에서 Cursor하는 방식
- 개선 전 ItemReader
![]()
- 개선된 ItemReader
![]()
- Data Aggregation
- 통계 처리 -> Batch 처리 -> Database GroupBy & Sum
- sum 쿼리에 의존하는 Batch 문제점
- 다양한 테이블 Join
- Group By Temporary / fileSort
- => 테이블 조회 속도 느려짐
- 연산 과정이 쿼리에 의존적
- 데이터 누적
- 쿼리 튜닝 난이도
- 중복도 변경
- 과한 인덱스 추가
- Group By를 포기한다…
- 쿼리는 단순하게
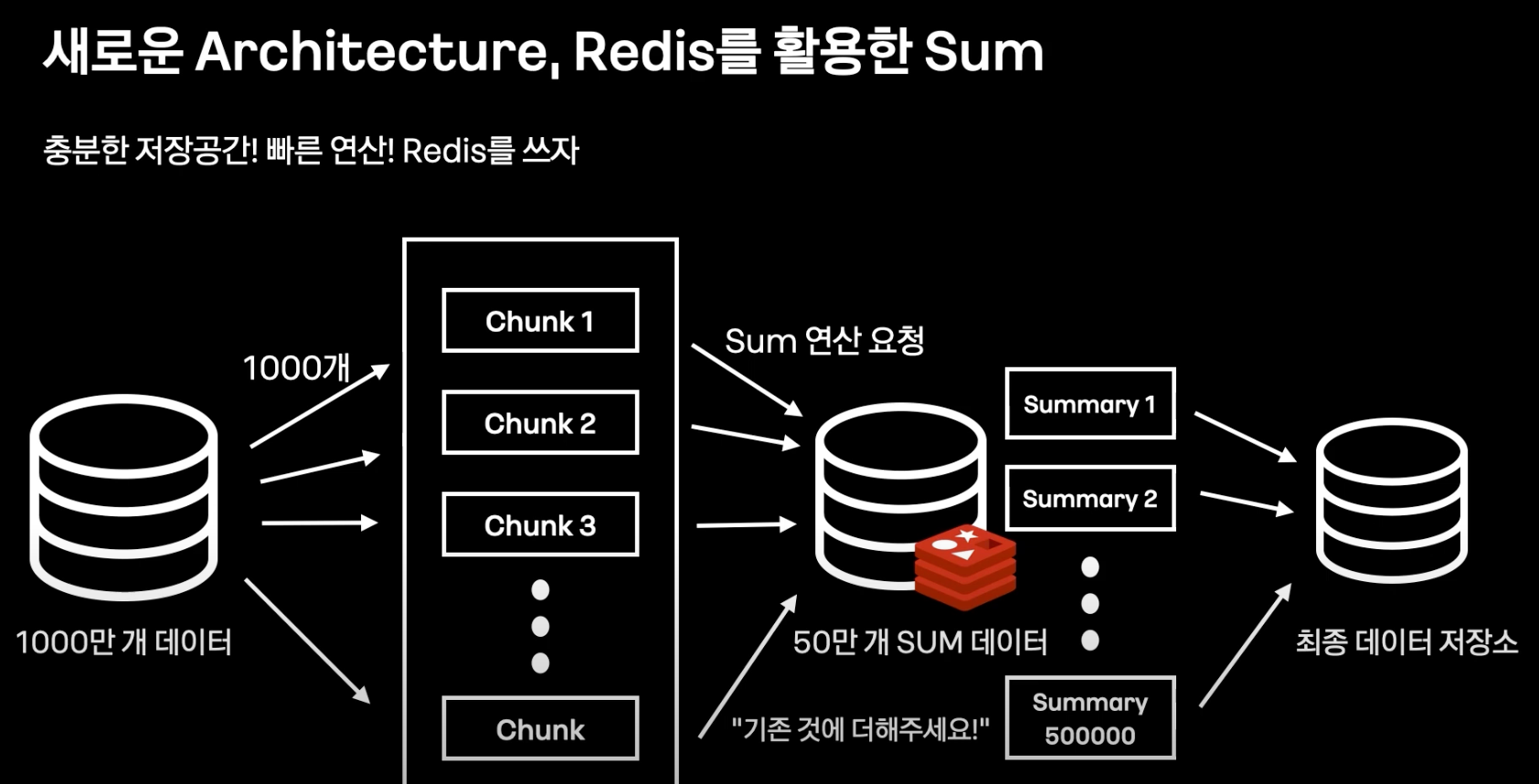
- 1000만개의 데이터를 50만개로 Aggregation 하기엔 서버 부하가 큼
- -> 새로운 아키텍처 필요
- Redis를 사용
![]()
- 연산 API 지원
- 메모리 수준 합산
- 50만개 쉽게 넉넉한 메모리
- In-Memory DB / 빠른 저장 0 영구 저장 X
- 해결되지 않는 문제
- 너무 네트워크 I/O
- 네트워크 Latency
- 해결 -> Redis Pipeline 한번에 처리해서 IO를 줄임
- Redis를 사용
- Data Write
- Batch Insert
- 명식적 쿼리
- 영속성 컨텍스트 사용하지 않는다.
- JPA bye…
- Dirty Checking / 영속성관리 필요없음
- Read할 때부터 Dirty Checking 버리기 / Projections 사용하기
- Update를 불필요한 필드도 Update
- Dynamic Update가 있지만 동적 쿼리 생성때메 오히려 성능저하 가능성
- Batch Insert 지원이 힘듦
- IDEntiTY ID 전략은 Batch insert 불가
- 배치 구동 환경
- Crontab, Airflow, Jenkins
- 실행요청, 스케줄, Batch 괸리, 워크 플로우 관리, 모니터링, 히스토리 등 관리 제공
- Batch 상태 파악의 어려움
- Spring Cloud Data Flow를 구축
- 데이터 수집, 분석, 데이터 I/O 데이터 파이프라인을 만들고 오케스트레이션
- 데이터 파이프 라인 종류
- Stream
- Task(Batch)
- K8s 완벽한 연동 batch 실행 오케스트레이션
- Spring Batch와 완벽한 호환 유용한 정보 시각적 모니터링
- Crontab, Airflow, Jenkins


정리
대량 데이터 Read
- ZeroOffsetItemReader
- CursorItemReader
데이터 Aggregation 처리
- 쿼리 의존도 down
- Redis를 통한 Aggregation
대량 데이터 Write
- Batch Insert 사용
구동 환경
- Spring Cloud Data Flow
- Batch 오케스트레이션, 모니터링 히스토리 강화