
Why Kafka is fast?
유튜브를 보던 중 추천 영상으로 떠서 보게되어 간단하게 정리해봤습니다.
카프카가 빠르다는 의미는 무엇일까? 낮은 레이턴시? 많은 데이터 전송 처리? 카프카는 높은 데이터 전송 처리를 위해 최적화 되었습니다. 카프카는 많은 수의 레코드(데이터)를 짧은 시간에 처리하도록 디자인되었습니다.
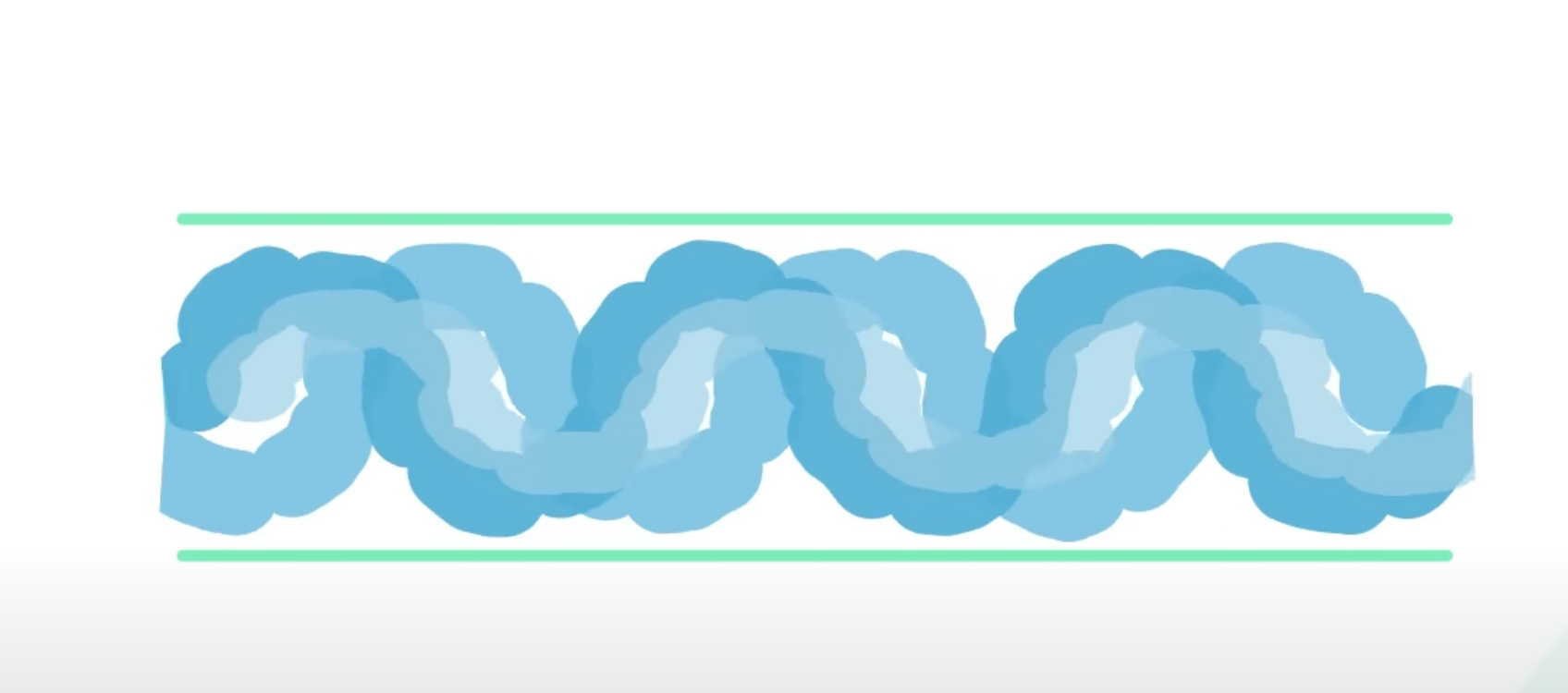 직경이 큰 파이프에 액체가 많이 이동한다고 생각해보세요. 그래서 누군가 카프카가 빠르다고 말하면 주로, 많은 데이터를 보내는 카프카의 성능을 말하는 것이다.
직경이 큰 파이프에 액체가 많이 이동한다고 생각해보세요. 그래서 누군가 카프카가 빠르다고 말하면 주로, 많은 데이터를 보내는 카프카의 성능을 말하는 것이다. 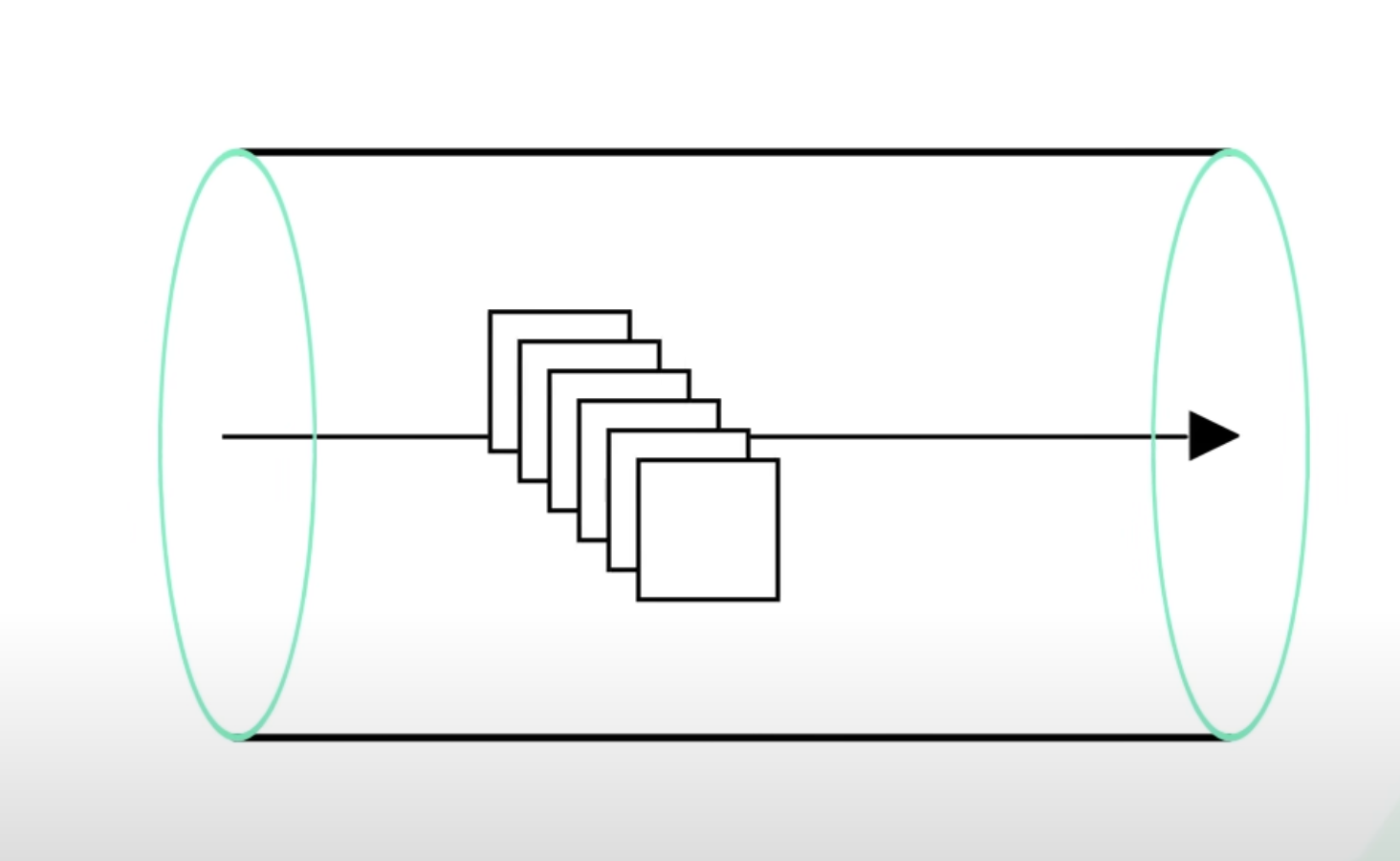
어떠한 디자인 결정이 많은 데이터를 카프카가 효과적으로 처리할 수 있게 하였을까요? 카프카의 성능을 위해 많은 컨트리뷰터가 디자인 결정을 했지만 두가지를 집중해보겠습니다.
1. 카프카는 Sequential I/O입니다.
기본적으로 디스크 접근은 메모리 접근보다 느립니다. 그러나, 데이터 접근 패턴에 따라 차이가 큽니다. 디스크 접근 패턴에는 두가지가 있습니다.
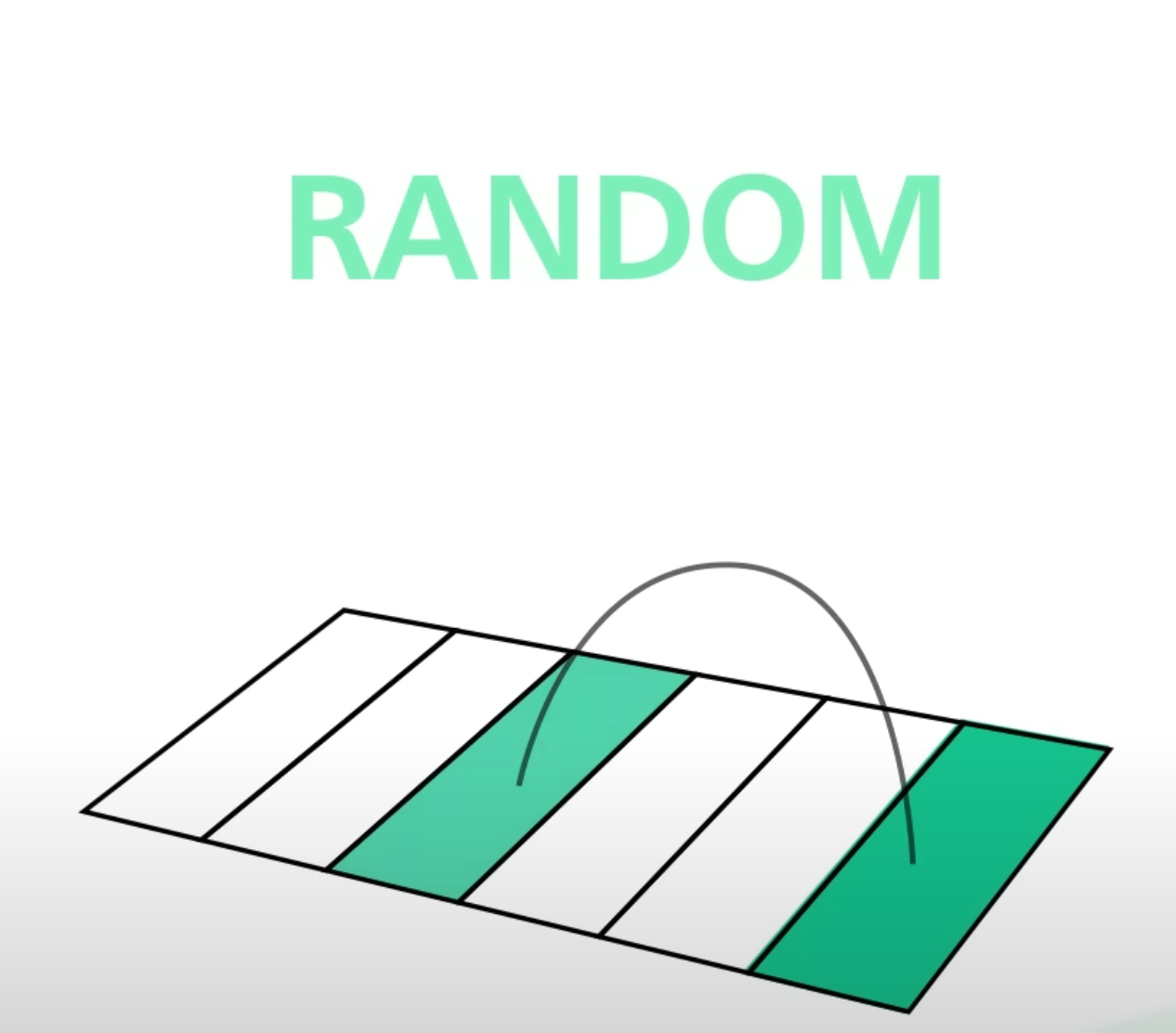
- Random Access Pattern
- 메모리에 랜덤하게 접근하는 방법
- 물리적으로 다른 위치로 이동합니다
![Screen Shot 2022-07-30 at 23.03.58.png]()
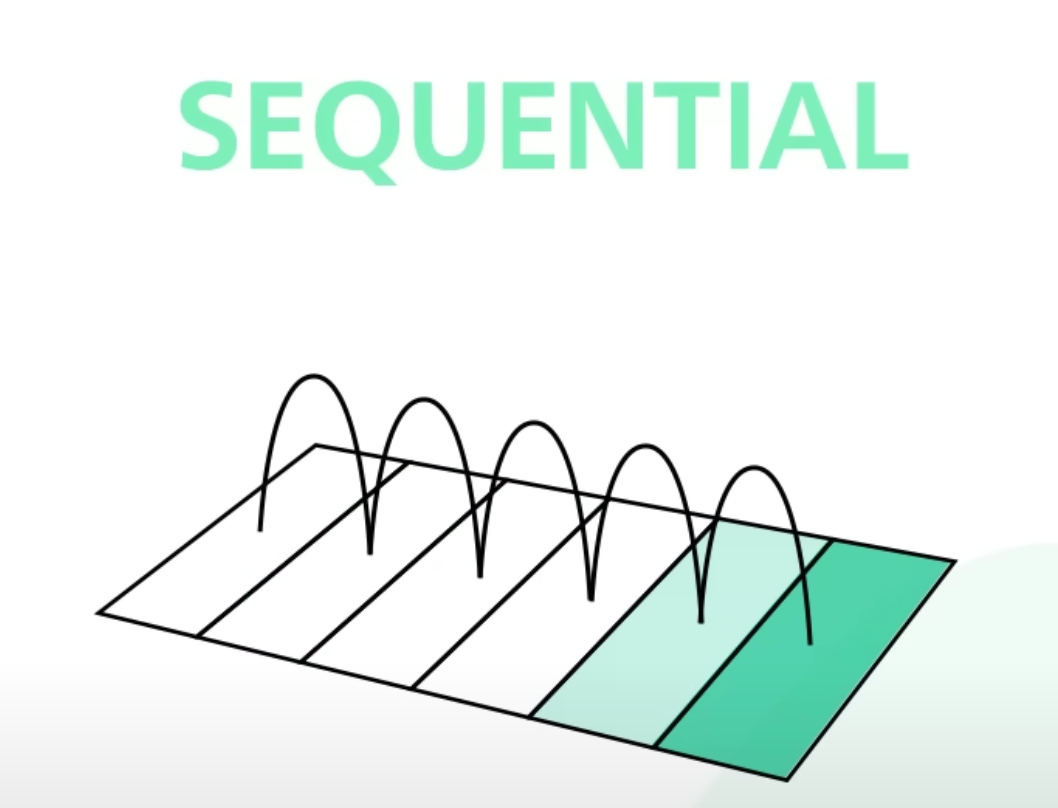
- Sequential Access Pattern
- 메모리에 순차적으로 접근하는 방법
- 바로 다음 위치로 이동하여 Random Access Pattern 보다 빠릅니다.
![Screen Shot 2022-07-30 at 23.04.51.png]() 개발자를 위한 SSD (Coding for SSD) - Part 5 : 접근 방법과 시스템 최적화
개발자를 위한 SSD (Coding for SSD) - Part 5 : 접근 방법과 시스템 최적화
카프카는 Append-only log를 사용하여 Sequential Access Pattern의 이점을 가졌습니다.
- 초당 속도 차이 카프카는 저렴한 디스크로 성능저하없이 쓸 수 있으며, 이것은 카프카는 금액적으로도 효율적으로 메시지들을 오랜 기간동안 유지할 수 있습니다.
2. Zero Copy Principle (복사하지않는다!)
카프카는 네트워크와 디스크 사이에 많은 데이터 이동을 합니다. 이 때 많은 많은 데이터 복사가 이러납니다. 현대의 시스템은 디스크로부터 네트워크로 데이터를 보낼 때 과잉 데이터 복사가 없도록 최적화되었습니다.
- without Zero Copy Principle
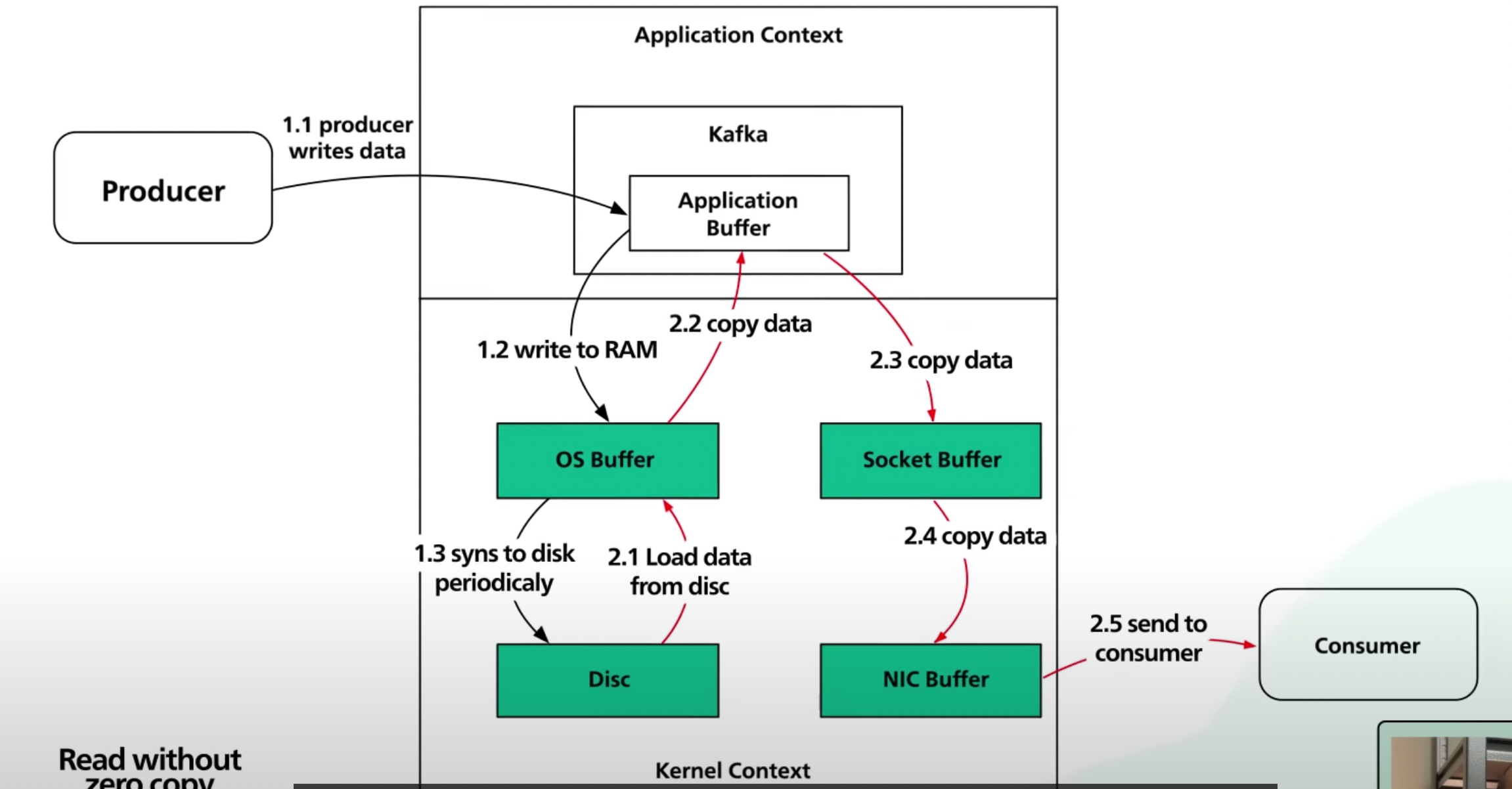
OS 레벨에서 4번의 복사와 2번의 시스템 호출이 이러납니다.
- with Zero Copy Principle
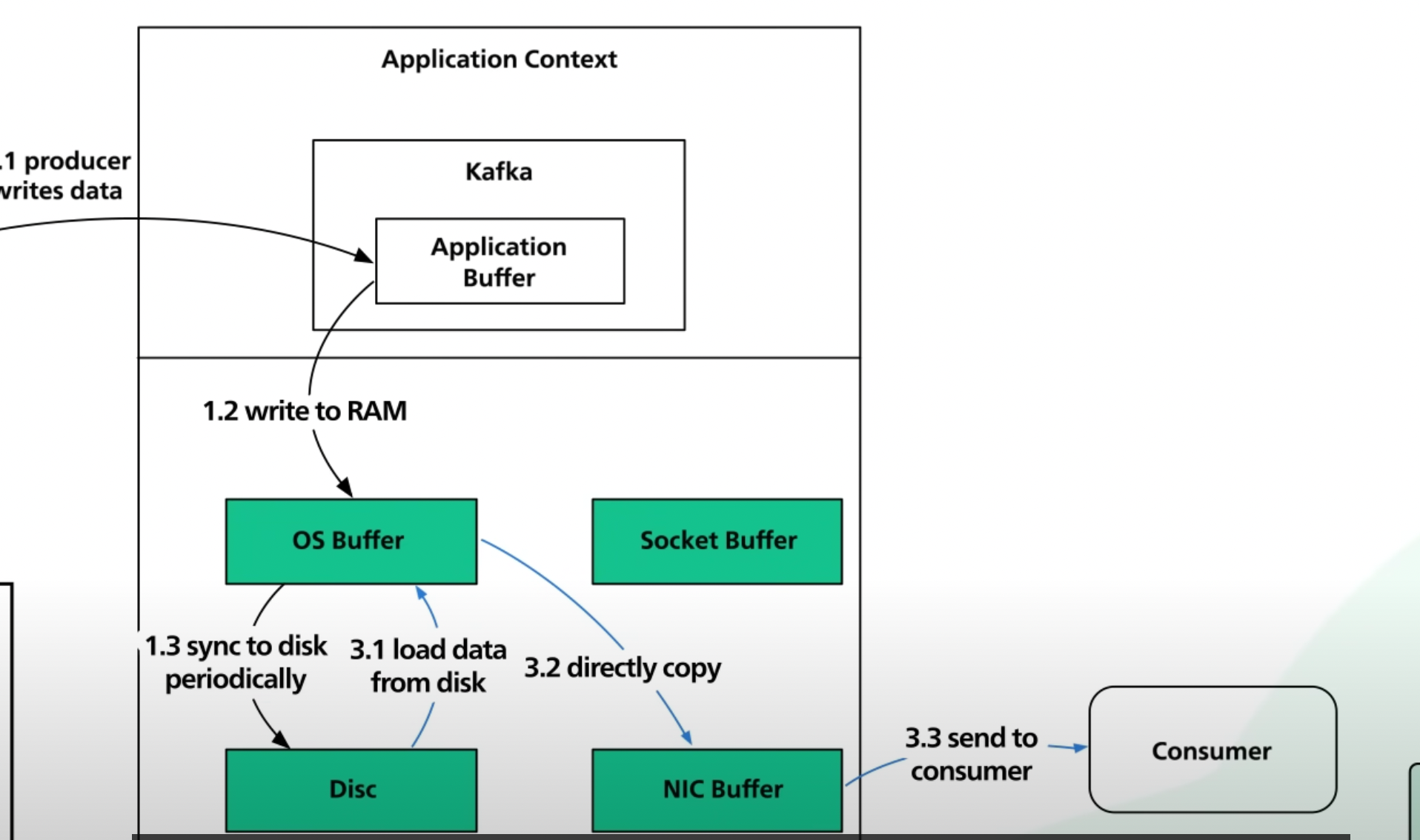
첫번 째 Disk로부터 OS Buffer로 데이터를 로드하는 과정은 같습니다.
Zero Copy는 카프카 애플리케이션은 sendfile() 이라는 시스템 호출을 사용하여 OS에게 곧바로 NIC Buffer로 데이터를 복사할 수 있습니다 . 이런 방법은 OS Cache에서 네트워크 카드 Buffer로 단 한번의 복사만 이러납니다. 현대의 네트워크 카드는 DMA로 데이터를 복사합니다.
DMA : Direct Memory Acess
위 두 가지 Sequential I/O 와 Zero Copy Principle가 카프카의 높은 성능에 기초가 됩니다. 카프카는 높은 성능을 위해 많은 다양한 기술을 짜내서 쓰지만, 다른 것들 보다 위 두 가지가 제일 중요해 보입니다.
References
https://www.youtube.com/watch?v=UNUz1-msbOM
스루풋 - 위키백과, 우리 모두의 백과사전
직접 메모리 접근 - 위키백과, 우리 모두의 백과사전
Zero-copy - Wikipedia